
4o-image-generation
OpenAI于2025年3月25日推出了其最新的图像生成能力,该功能集成于 GPT-4o 模型中。OpenAI长期以来认为图像生成应该是其语言模型的主要能力之一,而GPT-4o代表了他们迄今为止最先进的图像生成器,其目标是生成 不仅美观而且实用 的图像。
与以往侧重于超现实或令人惊叹的场景的生成模型不同,GPT-4o的图像生成更侧重于实用性,能够生成人们在分享和创建信息时使用的“主力”图像。这包括从徽标到图表的各种图像,这些图像在与共享语言和经验相关的符号结合时,可以传达精确的含义。
GPT-4o的图像生成在多个方面进行了改进,使其在实用性和功能性上都更上一层楼:
- 文本渲染:GPT-4o能够准确地渲染文本,并能精确地遵循提示。它具备将精确的符号与图像融合的能力,将图像生成转变为视觉交流的工具。例如,它可以生成带有清晰可读文字的街道路牌、菜单和邀请函。
- 多轮生成:由于图像生成现在是GPT-4o的原生能力,因此可以通过自然对话来改进图像。GPT-4o可以基于聊天上下文中的图像和文本进行迭代,确保整个过程的一致性。例如,在设计视频游戏角色时,即使经过多次修改和实验,角色的外观也能保持连贯.
- 指令遵循:GPT-4o的图像生成能够遵循详细的提示,并注重细节。与其他系统在处理5-8个对象时可能遇到困难不同,GPT-4o可以处理多达10-20个不同的对象。对象与其特征和关系之间更紧密的结合使得控制更加精细。
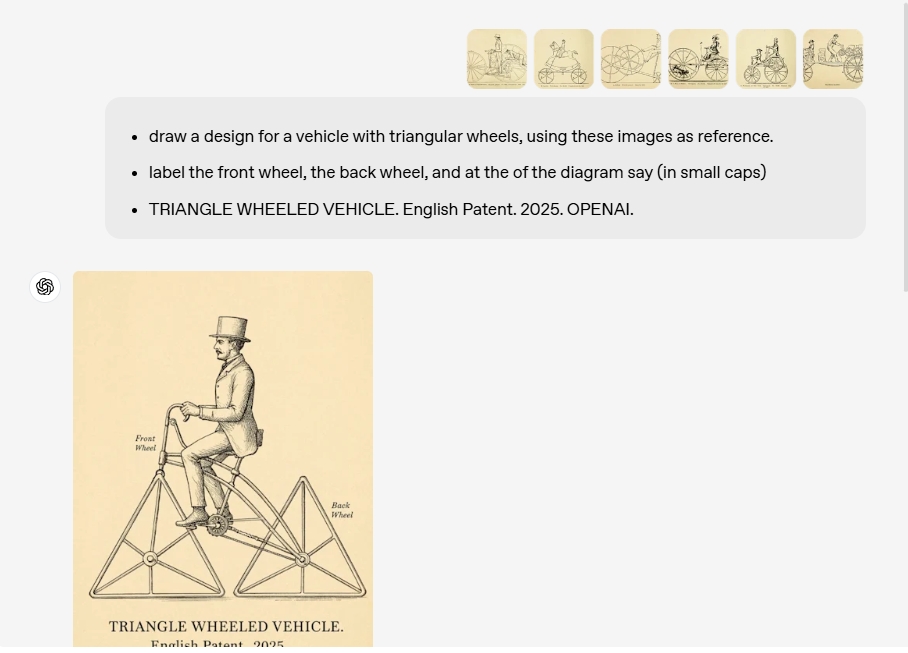
- 上下文学习:GPT-4o可以分析和学习用户上传的图像,并将其细节无缝集成到上下文中,从而为图像生成提供信息。这意味着您可以上传一张图片作为参考,并要求GPT-4o生成具有相似风格或特征的新图像。
- 世界知识:原生的图像生成能力使GPT-4o能够连接其文本和图像之间的知识,从而使其感觉更智能、更高效。这使得它可以根据代码生成图像,创建带有食谱标签的鸡尾酒专业照片级图表,生成旧金山雾天原因的可视化信息图,以及制作不同类型鲸鱼的教育海报等.
GPT-4o在大量不同图像风格的数据上进行了训练,使其能够令人信服地创建或转换图像。这包括生成各种风格的图像,例如模仿抓拍的狗仔队照片、宝丽来风格的照片、老式胶片照片,以及高度逼真的场景和物体。
OpenAI也承认其模型并非完美,目前存在一些局限性,他们将在发布后通过模型改进来解决这些问题:
- 裁剪:GPT-4o有时可能会过度裁剪较长的图像,尤其是在底部附近。
- 幻觉:与其他文本模型类似,图像生成也可能编造信息,尤其是在上下文信息较少的提示下。
- 高绑定问题:在生成依赖其知识库的图像时,模型可能难以一次准确渲染超过10-20个不同的概念,例如完整的元素周期表。
- 精确绘图:模型在生成精确的图表时可能存在困难。
- 多语种文本渲染:模型有时难以渲染非拉丁语言,字符可能不准确或出现幻觉,尤其是在更复杂的情况下。
- 编辑精度:对图像生成的特定部分(例如错别字)进行编辑的请求有时效果不佳,并且可能以非请求的方式更改图像的其他部分或引入更多错误。模型在保持用户上传面部编辑的一致性方面存在一个已知bug,但预计在一周内修复。
- 小文本中的密集信息:当要求以非常小的尺寸渲染详细信息时,模型已知会遇到困难。